Ollama 入门:在本地跑 AI 模型,其实很简单
从零开始,学会安装 Ollama、下载模型、跑通第一次对话,避开新手常见坑。
什么是 Ollama?
Ollama 是一个帮你轻松在本地电脑上运行 AI 模型(比如 Llama、Mistral)的工具。你可以把它理解成“AI 模型的 Docker”——下载、运行一条命令搞定,不需要自己配置复杂的环境。它底层用的是 llama.cpp(一个让大模型在普通电脑上也能跑起来的引擎),所以即使你没有高端显卡,也能用 CPU 运行,只是速度会慢一些。

安装步骤
- 下载 Ollama:访问 ollama.com,点击 Download,选择你的操作系统(Windows、macOS 或 Linux)。Windows 用户下载 .exe 安装包,macOS 用户下载 .dmg,Linux 用户可以用一行命令安装。
- 运行安装程序:双击安装,一路默认即可。安装完成后,Ollama 会自动在后台启动,你可以在终端(命令提示符)里输入
ollama --version检查是否安装成功。 - 下载一个模型:打开终端,输入
ollama run llama3.1。这会自动下载一个叫 Llama 3.1 的模型(大约 4.7GB),然后直接进入对话界面。如果嫌大,可以先试试ollama run phi3(约 2.3GB),更轻量。
第一次跑通
下载完成后,你会看到类似 >>> Send a message 的提示。直接输入你的问题,比如“什么是人工智能?”,模型就会开始回答。按 Ctrl+D 退出对话。
常见坑提醒:Ollama 默认只记住最近 2048 个 token(约 1500 个汉字)。如果你粘贴一段很长的代码,它可能会“忘记”前面部分。解决方法:运行模型时加上参数,比如 ollama run llama3.1 --num-ctx 8192,把上下文窗口扩大到 8192 token。

硬件要求与速度
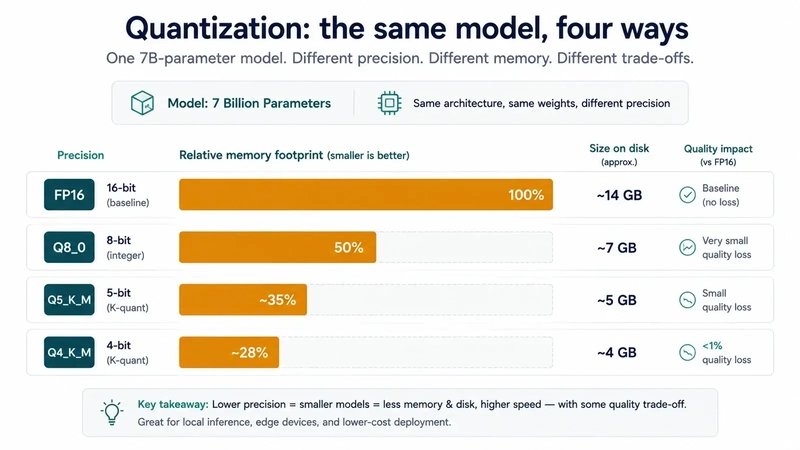
模型跑得快不快,主要看你的 显存(显卡内存)。以 Q4_K_M 量化格式(一种压缩方式,几乎不影响质量)为例:70 亿参数的模型需要约 4.2GB 显存,130 亿参数需要约 7.8GB。如果显存不够,Ollama 会自动切换到 CPU 运行,速度会降到每秒 10-20 个 token(一个字一个字蹦),但能用。如果你有 NVIDIA 显卡(比如 RTX 3060 以上),速度可以达到每秒 40-80 个 token,非常流畅。
内容来源
DEV Ollama
发布时间
2026-06-17 01:32