AI 入门:在笔记本上搭建本地推理服务器
手把手教你装好 Ollama,在笔记本上跑通第一个 AI 模型,避开新手常见坑。
你是不是也想在本地跑个 AI 模型,但被各种教程绕晕了?别怕,这篇教程就是给你准备的。你不需要高端显卡,也不用懂 Linux 内核,一台普通笔记本就行。读完这篇,你就能在电脑上装好 Ollama,跑通第一个模型,还能让它输出格式化的结果。
准备环境
首先,你需要一个操作系统。推荐用 Ubuntu(一个免费的开源系统),因为它的驱动支持和社区帮助最完善。如果你现在用的是 Windows,可以装个虚拟机或者直接双系统。当然,如果你熟悉 Linux,也可以用 Debian(Ubuntu 的爸爸系统)或者 Parrot OS(一个自带安全工具的系统)。但新手别折腾,先上 Ubuntu 最稳。
硬件方面,你至少需要 8GB 内存,最好有 16GB。显卡?有 NVIDIA 显卡最好,没有也能跑,只是慢一点。硬盘留出 20GB 空间就行。
安装 Ollama
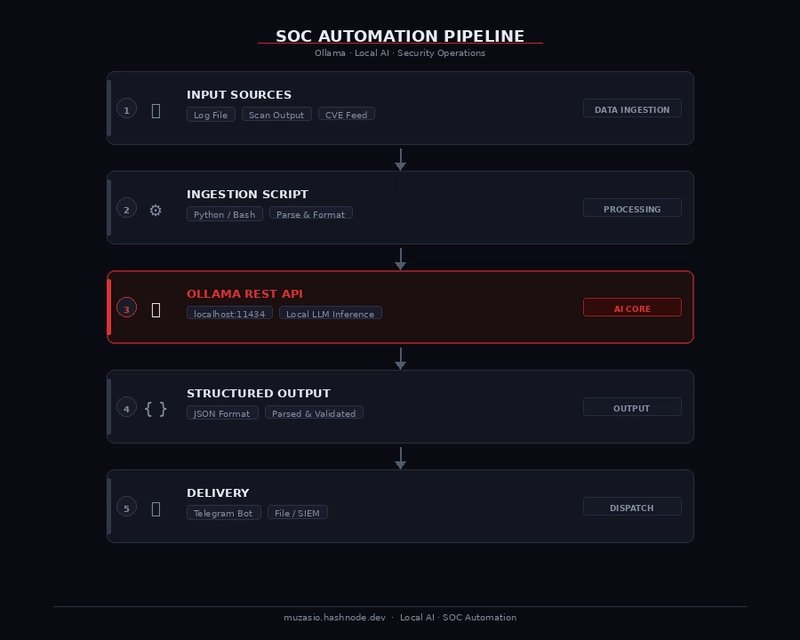
Ollama 是一个让你在本地轻松运行大语言模型的工具。一句话解释:它就像 AI 模型的“App Store”,你下载一个命令就能装上模型,然后通过 API 跟它聊天。

- 打开终端(Ctrl+Alt+T)。
- 输入以下命令,一键安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh - 安装完成后,输入
ollama --version检查是否成功。如果显示版本号,说明装好了。
常见坑:如果你有 NVIDIA 显卡,还需要装 nvidia-container-toolkit(一个让 Docker 容器使用 GPU 的工具),否则模型会跑在 CPU 上,慢很多。命令如下:
sudo apt install nvidia-container-toolkit然后重启 Docker 服务:sudo systemctl restart docker
跑通第一个模型
Ollama 装好后,我们来下载并运行一个模型。新手推荐 llama3.2(一个轻量级模型,只有 3B 参数,适合入门)。
- 在终端输入:
ollama run llama3.2 - 第一次运行会自动下载模型(大约 2GB),等几分钟。
- 下载完后,你会看到一个提示符,直接打字跟它聊天就行!比如输入“你好”,它就会回复。
常见坑:模型跑了几次后可能会变慢或者卡住。这是因为默认设置没调好。你可以在运行前设置 上下文窗口大小(模型一次能记住多少字)和 温度(回答的随机性)。简单调一下:ollama run llama3.2 --context-size 2048 --temperature 0.7。这样更稳定。
验证成功与下一步
你可以在终端里连续问几个问题,看回答是否顺畅。如果一切正常,恭喜你,你已经成功在笔记本上跑起了本地 AI!
下一步,你可以尝试用 curl 命令通过 API 调用模型,这样就能把它集成到你的自动化脚本里。比如:
curl http://localhost:11434/api/generate -d '{"model": "llama3.2", "prompt": "用 JSON 格式输出一个待办事项列表"}'注意:默认输出可能不总是 JSON,需要你调教提示词(prompt),比如明确要求“只输出 JSON”。另外,建议把 Ollama 装在 Docker(一种容器技术,让应用隔离运行)里,这样更安全,不会因为脚本错误影响整个系统。
好了,你已经迈出了 AI 入门的第一步。接下来可以试着用 n8n(一个自动化工作流工具)或者 Fabric(一个命令行 AI 框架)来搭建更复杂的应用。加油!
内容来源
DEV Ollama
发布时间
2026-06-10 01:32