AI 入门:在 3090 上同时跑语音识别和语言模型
学会用 Ollama 在单张 3090 显卡上同时部署 WhisperX 语音识别和 24B 大语言模型,包含环境安装、配置优化和验证步骤。
准备环境
你需要一台装有 NVIDIA 显卡(显卡是专门做图形和深度计算的核心硬件,比如 RTX 3090)的电脑,并安装好 NVIDIA 驱动(让操作系统和显卡通信的软件)和 CUDA(NVIDIA 的并行计算平台,让 AI 模型能利用显卡加速)。确保 nvidia-smi 命令能正常显示显卡信息。
安装 Ollama(一个让本地运行大语言模型的工具,类似应用商店,帮你下载和管理模型)。去 ollama.com 下载对应系统的安装包,直接安装即可。
安装步骤
- 下载语音识别模型 WhisperX:打开终端,运行
ollama pull whisperx,等待下载完成(约 3GB)。 - 下载大语言模型:运行
ollama pull devstral:24b-q4_K_M,这是 24B 参数的模型,量化后约 15GB。 - 创建上下文裁剪版模型:为了节省显存,我们创建一个只保留 8192 个上下文窗口(模型一次能“记住”的文本长度)的版本。新建文件
Modelfile,内容如下:FROM devstral:24b-q4_K_MPARAMETER num_ctx 8192SYSTEM """You are a helpful assistant.""" - 生成新模型:在终端运行
ollama create triage -f Modelfile,这会创建一个名为triage的新模型。 - 启动服务:分别运行
ollama run whisperx和ollama run triage,两个模型会同时加载到显卡上。
验证是否成功
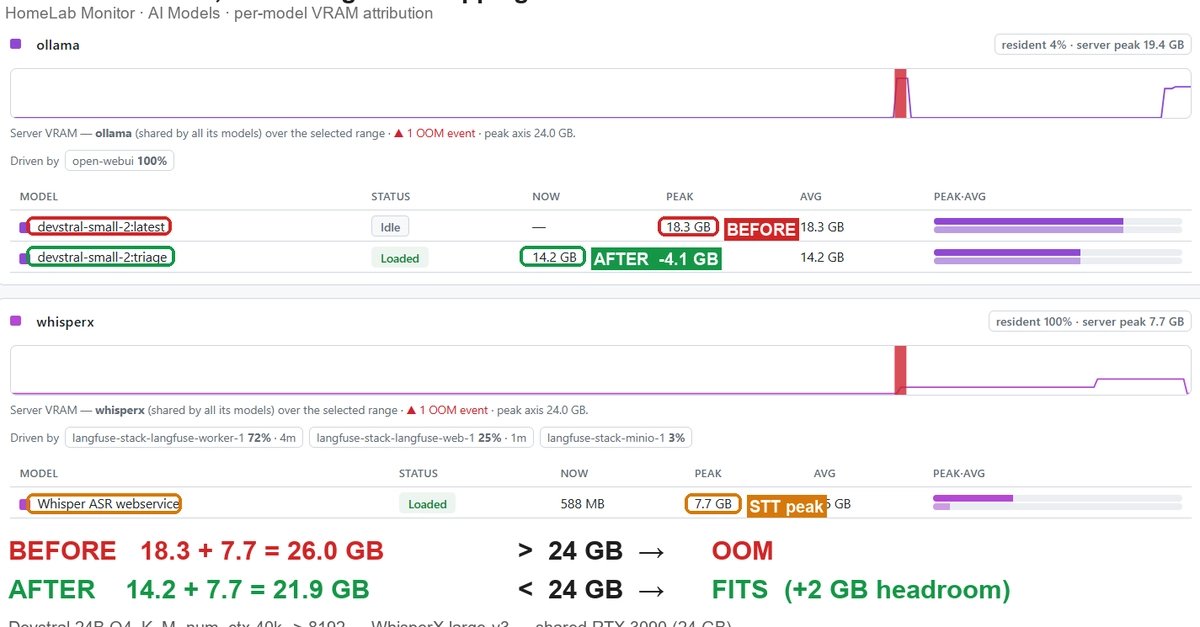
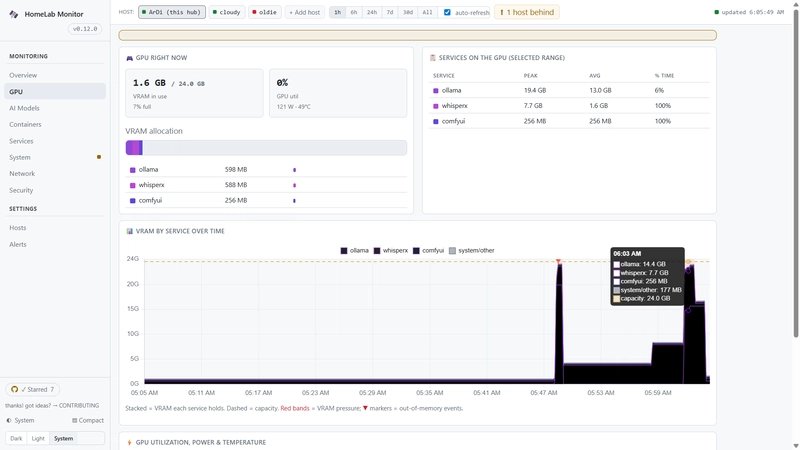
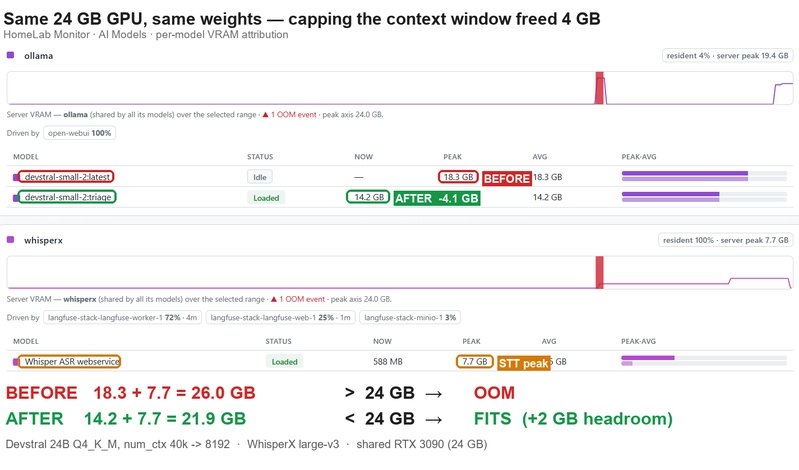
打开另一个终端,运行 nvidia-smi 查看显存占用。你应该看到两张卡(如果有的话)或单卡上显存占用约 14-16GB(WhisperX 约 2GB,triage 约 14GB),总占用不超过 24GB(3090 有 24GB 显存)。如果显存溢出(OOM),可以进一步降低 num_ctx 到 4096,但可能影响长文本处理。
下一步可以做什么
你可以用 Ollama 的 API 调用这两个模型:语音文件传给 WhisperX 转文字,然后文字传给 triage 模型做摘要或分类。具体代码参考 homelab-monitor 项目,它提供了一个仪表盘实时监控显存使用。
内容来源
DEV Ollama
发布时间
2026-06-04 01:31